꿀팁4 GPT 뉴스 크롤링 프로그램 만들기
2024-09-08 21:02:11
GPT는 진입 장벽을 확! 낮추었습니다. 비개발자도 쉽게 웹페이지 크롤링 프로그램을 만들 수 있습니다. GPT 뉴스 크롤링 프로그램 개발 방법을 설명드리겠습니다.
GPT 뉴스 크롤링 프로그램 만들기 준비 도구 설명
코랩
파이썬 프로그램을 웹페이지에서 실행할 수 있습니다.
회원가입만 하면 바로 이용 가능합니다.
파일 업로드도 가능하고 파일 생성도 가능합니다.
ngrok을 이용하면 외부에서도 접근하는 서버로도 활용할 수 있습니다.
서비스를 런칭하기는 어렵겠지만 파이썬 테스트 서버로서 아주 휼륭합니다.
연합뉴스
연합뉴스 홈페이지를 이용하겠습니다.
프로그램 설명
연합뉴스 오늘자 뉴스를 제목과 링크를 추출하여 로그로 출력하는 프로그램을 만들어 보겠습니다.
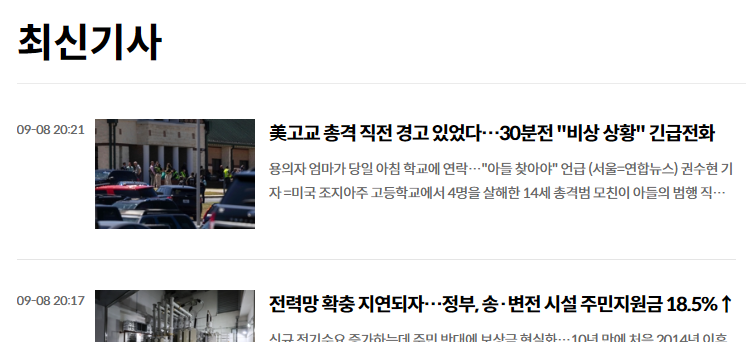
연합뉴스 오늘자 기사 목록 페이지를 오른쪽 클릭하여 소스 보기를 하겠습니다.

아래와 같이 뉴스 기사와 링크를 복사하여 GPT 요청 구문에 사용하겠습니다.
GPT에서 아래와 같이 요청하겠습니다.
https://www.yna.co.kr/news?site=navi_latest_depth01
위 링크의 뉴스 제목과 링크를 로그로 출력하는 파이썬 프로그램을 만들어 줘.
예를 들어 웹페이지의 소스가 아래와 같다면
<a href="https://www.yna.co.kr/view/AKR20240908049700009" class="tit-wrap">
<strong class="tit-news">美고교 총격 직전 경고 있었다…30분전 "비상 상황" 긴급전화</strong>
美고교 총격 직전 경고 있었다…30분전 "비상 상황" 긴급전화, https://www.yna.co.kr/view/AKR20240908049700009
라고 로그를 찍으면 돼.
코랩에서 실행하는 코드로 작성해.
GPT가 소스코드를 작성해 주는데 코랩에서 실행해보면 뉴스 제목과 링크가 출력되지 않았습니다.
그래서, 아래와 같이 추가 요청했습니다.
로그가 안 찎혀
그러면, 아래와 같이 정상 동작하는 코드가 작성됩니다.
!pip install requests beautifulsoup4
import requests
from bs4 import BeautifulSoup
# URL 설정
url = 'https://www.yna.co.kr/news?site=navi_latest_depth01'
# 웹페이지 가져오기
response = requests.get(url)
response.encoding = 'utf-8' # 한글 인코딩
# BeautifulSoup으로 HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 뉴스 제목과 링크 추출
for news in soup.find_all('a', class_='tit-wrap'):
title = news.find('strong', class_='tit-news').get_text(strip=True)
link = news['href']
# 링크가 절대 URL이 아니면 도메인 추가
if not link.startswith('http'):
link = 'https://www.yna.co.kr' + link
# 제목과 링크 출력
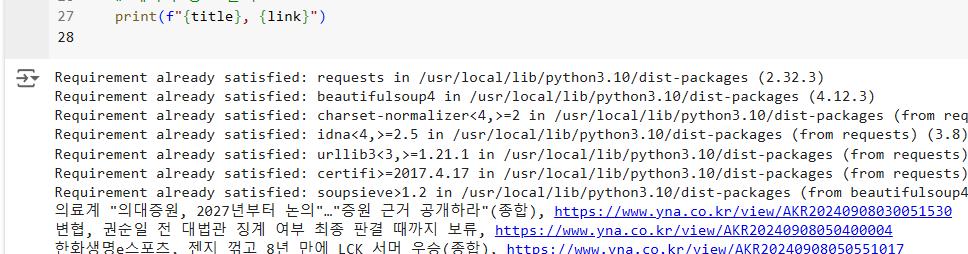
print(f"{title}, {link}")
아래와 같이 로그 출력이 확인 됩니다.
꿀팁1 GPT 데이터 분류하기
꿀팁2 GPT 구글시트 플러그인
꿀팁3 GPT 데이터 분석
꿀팁4 GPT 데이터 분석 그래프 한글 깨짐 해결 방법